For us, D-Day started relatively calmly. All servers in all 3 geographical zones were up and running, pre-warmed, and waiting for the expected onslaught. At Noon UTC, the first players started streaming in, and during the ramp-up, all systems were holding well, with no critical automatic alerts being generated in our monitoring systems.
—–
After about an hour, we started noticing that servers handling some of the more populated zones were starting to grow an alarming number of NPCs with a commensurate effect on performance. At the same time, early signals from the ground that we obtained through Discord started mentioning heavy rubber-banding in some zones which would be an expected consequence.
Those familiar with our military history from Alpha might remember that a runaway population of rabbits once brought us to our knees. In this case, it wasn’t specifically rabbits, but a more general swarming of mobs that apparently was triggered by a dense and very active player population where our population control was not able to keep up with the spawning of mobs.
As a temporary fix, while we were troubleshooting, we started identifying those servers that were on the brink and selectively restarting them. This meant a brief disconnect for players connected to those zones, but at least the server temporarily went back to a sane state.
Fortunately, we had been working on possibly fixing this in the previous days though we had never been really able to reproduce this under lab conditions.
We decided to fast-track the fix, which was a server-only fix that did not require a patch from the client. Building and deploying the fix to our staging servers took roughly 2 hours. We then decided to deploy it selectively to a few of the worst zones to see if it fixed the issue before deploying it in general.
Deploying a hotfix live to our whole armada of servers is always a risky proposal, and in this case, we prefer applying it to a subset of servers out of caution. Furthermore, once deployed on a zone, we would have to wait at least an hour before we could ascertain that the fix was actually working. Until then we continued to manually restart zones in distress, which was an acceptable stop-gap solution.
—-
But in an invasion of this scale, we rarely have to face just one issue. From Discord we also started to receive reports of problems with recipe unlocks, with heavy delays involved in related operations.
Looking at our server, we already knew about one weak link in that system: our Redis server, which was used for replicating recipe notifications to all players (along with various other notifications, such as the damage state of party members, etc.).
This specific server can not scale simply by adding more hardware, so if it was reaching breaking limits, we would have to address it at a more fundamental level.
Again, we could temporarily mitigate the problem by restarting some related services, but we immediately started work on a more permanent fix, but that fix requires some more thorough testing before we can deploy it, so we will probably have to live with this instability one more day.
—
This distraction held our attention while a more fundamental problem was brewing under the surface and partially hidden in the fog of war. At around 16:50 UTC we started receiving reports from Discord that people had trouble placing plots and some were not seeing what they built while resources were still consumed. Originally, starting in the US region, this state also spread to the EU region but strangely left the SEA region unscathed. This battle ended up being the one that took most of our time and was the most difficult to troubleshoot, not resulting in a fix until around 02:00 UTC (D-Day + 1).
—
The culprit in this case was a link between our database and a service responsible for replicating building pieces to all players as they get built. The latter service is a managed service that has some pre-configured quota limits, which we hit at some point, leading to a throttling of the service.
Normally, this wouldn’t be a problem as we can dynamically increase the quota, but in this case, when the quota was increased and the database started communicating again with it, it had to restore a very large backlog of transactions that had piled up. Even though it was doing it diligently, it simply could not catch up, leading to very long delays between creating building blocks and replicating them to clients.
At some point, we could see a whole hour’s delay. So for players, it looked like they could not build a plot, but the reality is that they didn’t see the operation conclude until after more than an hour delay. This is all very obvious with the clarity of hindsight, but it took a while for us to troubleshoot this and find the root cause. As we were still in discovery mode, we opted on the side of caution and allowed the service to drain itself at its pace to make sure no player state got lost, which took a couple of hours.
–
Once we found the root cause, we had some simple fixes to the configuration that we applied and restarted the services involved. The building state was nearly immediately restored and all regions were back to normal after this.
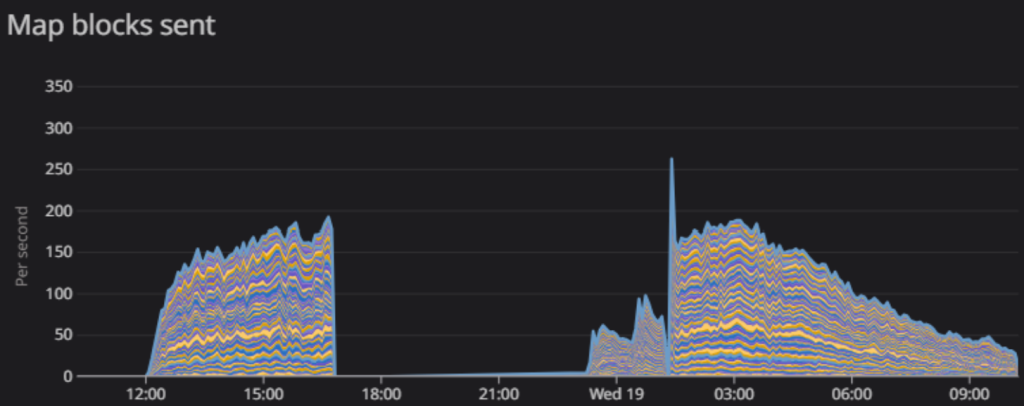
During all this, we had nearly forgotten about our initial worry: zone server performance due to mob population but we were happy to observe that after having applied the hotfix to selected zones, they seemed to be well under control and actually performing much better than before, which was great news. So, in parallel to all of the above, we started a rolling update of all zone servers across all our regions, which resulted in a brief disconnect for players while zones restarted but resulted in a much healthier CPU profile for all the worlds.
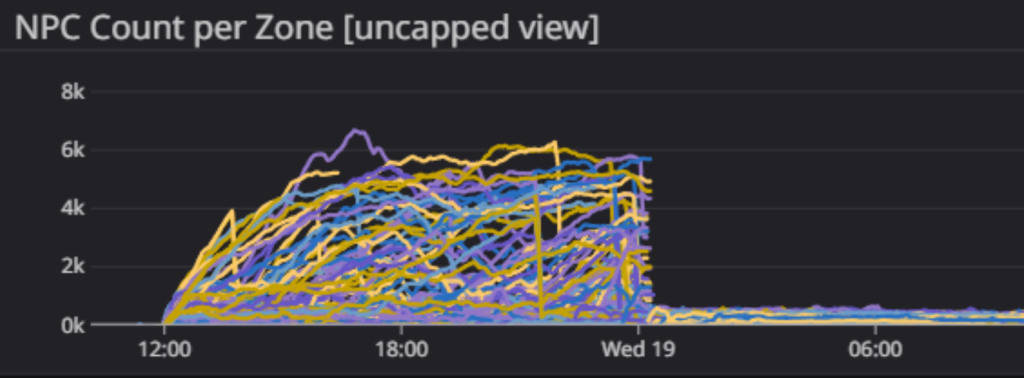
All in all, at 03:00 UTC (D-Day + 1) last night, after a nearly 24-hour shift, everyone in the War Room felt tired but happy. We could still hear some distant rumblings and we knew that the war was not over, but at least we had established our beachhead and were ready to move forward.
]]>